211service.com
Das Web in eine Tabelle einfügen
Riesige Datenmengen sind im Web frei verfügbar und können für viele Unternehmen eine potenzielle Fundgrube sein – vorausgesetzt, sie wissen, wie sie diese effektiv nutzen können.

Sortieren und filtern: BigSheets ermöglicht es Benutzern, unstrukturierte Daten aus dem Web mithilfe von Tools zu analysieren, die denen von Desktop-Tabellenkalkulationssoftware ähneln.
Ein Unternehmen kann beispielsweise vor dem Erwerb eines anderen Unternehmens Daten des US-Patent- und Markenamts und Gerichtsakten durchforsten, um zu sehen, ob sein geistiges Eigentum in rechtliche Schritte eingebunden ist. In der Praxis erfordert die Durchsicht so vieler Informationen jedoch Zeit und Mühe, um sie zu orchestrieren.
IBM hofft, dass ein neues Tool namens BigSheets , wird Benutzern helfen, Webdaten einfacher zu analysieren. Das Unternehmen hat eine Testversion der Software für die British Library entwickelt.
Die Fähigkeit eines jeden Benutzers, seine eigenen interessanten Analysen durchzuführen, wird langsam erwachsen, sagt Rod Smith, Vice President of Emerging Internet Technologies bei IBM.
BigSheets baut auf einer anderen Software namens Hadoop auf. Dabei handelt es sich um eine Open-Source-Plattform zur Verarbeitung sehr großer Webdatenmengen, indem Aufgaben aufgeteilt und an einen Cluster verschiedener Computer übergeben werden. Hadoop wird häufig verwendet, um große Mengen unstrukturierter Webdaten zu analysieren.
BigSheets verwendet Hadoop, um Webseiten zu durchsuchen und sie zu parsen, um Schlüsselbegriffe und andere nützliche Daten zu extrahieren. BigSheets organisiert diese Informationen in einer sehr großen Tabellenkalkulation, in der Benutzer sie mit den Tools und Makros analysieren können, die in Desktop-Tabellenkalkulationssoftware zu finden sind. Im Gegensatz zu gewöhnlicher Tabellenkalkulationssoftware gibt es jedoch keine Begrenzung für die Größe einer mit BigSheets erstellten Tabellenkalkulation.
Um BigSheets zu verwenden, würde ein Benutzer das Tool auf eine Reihe von URLs oder ein Datenrepository verweisen. Mithilfe von Begriffslisten können die Daten in Zeilen und Tabellen organisiert und später angepasst werden.
Smith sagt, dass IBM die Tabellenkalkulation als Modell zum Organisieren von Daten gewählt hat, weil die meisten Benutzer bereits mit einer solchen Software vertraut sind. Wenn Benutzer die Daten komplexer darstellen möchten, funktioniert das Tool mit einem IBM Visualisierungstool namens Viele Augen , sowie andere Visualisierungssoftware.
Tag team: Visualisierungstools können mit BigSheets verwendet werden, um Muster in unstrukturierten Daten zu finden.
BigSheets hat einen Integrationsgrad, den ich noch nicht gesehen habe, sagt Ich bin Lorica , Senior Analyst in der Forschungsgruppe des technischen Verlags O’Reilly Media. Traditionell, sagt Lorica, haben Unternehmen die Funktionen, die BigSheets ausführt, in drei separate Aufgaben aufgeteilt: Web-Crawling, Datenanalyse und Visualisierung. Da BigSheets auf Hadoop aufbaut, das grundsätzlich darauf ausgelegt ist, mit enormen Datenmengen zu arbeiten, sei die Skalierung für BigSheets kein Problem, sagt Lorica.
Er warnt jedoch davor, dass sich BigSheets in einem frühen Stadium befindet und mit anderen Daten getestet werden muss. Da die Technologie in Zusammenarbeit mit bestimmten Partnern von IBM entwickelt wird, sei unklar, wie einfach es für ein Unternehmen wäre, sie einzusetzen, sagt er. Das Einrichten eines Hadoop-Clusters kann eine anspruchsvolle Aufgabe sein, sagt er, und wenn BigSheets nicht gut verpackt ist, benötigen Unternehmen möglicherweise eine Armee von Beratern, um den Weg für das Tool vorzubereiten.
Den ersten Test für BigSheets gab es bei der British Library, die seit 2004 daran arbeitet, ein Archiv der rund acht Millionen britischen Websites aufzubauen. In regelmäßigen Abständen erstellt die Bibliothek Schnappschüsse von Webseiten, konvertiert sie in ein Archivdateiformat und speichert sie. Aber das Durchsuchen und Analysieren dieser Daten ist eine weitere Herausforderung, und hier kam BigSheets ins Spiel.
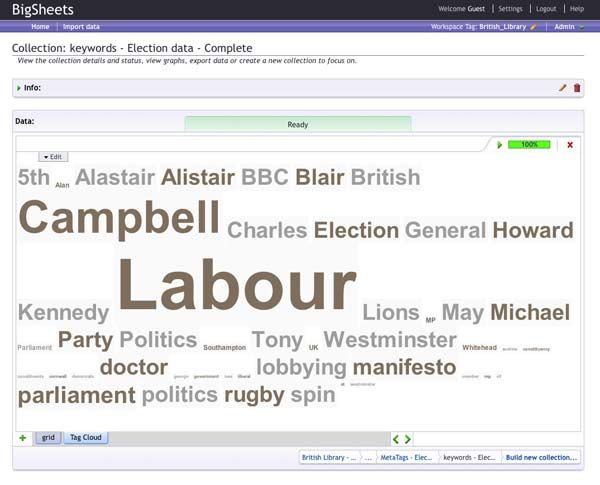
In weniger als acht Stunden, sagt Smith, hat sein Team 4,5 Terabyte an Archivdateien genommen und sie mit einem Hadoop-Cluster von vier Maschinen verarbeitet. Unter Anleitung von Forschern der British Library verwendete das Team BigSheets, um Schlüsselwörter, Autoreninformationen und andere Metadaten aus diesen unstrukturierten Webseiten zu extrahieren. Sie experimentierten mit Begriffshäufigkeitsanalysen und führten Tag-Clouds und andere Visualisierungen aus.
Die Forscher der British Library konnten im Laufe des ersten Tages die Art der Metadaten, die sie interessierten, anpassen und sich stärker darauf konzentrieren, wer die Seiten verfasst hatte, als ursprünglich beabsichtigt. Visualisierungen lieferten neue Erkenntnisse. Beispielsweise entdeckten die Forscher mithilfe einer Tag-Cloud, dass der Name der britischen Politikerin und Autorin Alastair Campbell wurde oft als Alistair falsch geschrieben, wodurch eine große Anzahl relevanter Datensätze ans Licht kam, die leicht hätte übersehen werden können.
Eytan Adar , ein Assistenzprofessor für Informations- und Informatik an der University of Michigan, der sich mit Internet-Scale-Systemen, Text Mining und Visualisierung befasst, sagt, dass das Tool eine große Wirkung haben könnte. Obwohl der Inhalt der British Library auf einige Schnappschüsse für jede Seite beschränkt zu sein scheint, bedeutet dies immer noch eine Menge Daten, und es ist nicht sinnvoll, Suchergebnisse als Antwort auf eine Abfrage einfach auszugeben, sagt Adar.
Adar hat sein eigenes Tool entwickelt, genannt Zoetrop , um zu analysieren, wie sich Webseiten im Laufe der Zeit verändert haben. BigSheets bringt neue Erkenntnisse, sagt er, indem es Daten von vielen verschiedenen Seiten sowie im Zeitverlauf vergleicht. Adar sagt, dass effektive Visualisierungen entscheidend sind, damit Benutzer große Datensammlungen schnell verstehen können.
Nach weiteren Tests hofft IBM, BigSheets in seine bestehenden Services und Produkte integrieren zu können.