211service.com
Google DeepMind bringt Maschinen mit künstlicher Intelligenz das Lesen bei
Eine Revolution der künstlichen Intelligenz fegt derzeit durch die Informatik. Die Technik heißt Deep Learning und betrifft alles von Gesichts- und Stimmbildung bis hin zu Mode und Wirtschaft.
Aber ein Bereich, der noch nicht davon profitiert hat, ist die Verarbeitung natürlicher Sprache – die Fähigkeit, ein Dokument zu lesen und dann Fragen dazu zu beantworten. Das liegt zum Teil daran, dass Deep-Learning-Maschinen ihr Handwerk zunächst aus riesigen Datenbanken lernen müssen, die für diesen Zweck sorgfältig kommentiert werden. Diese sind jedoch einfach nicht in ausreichender Größe vorhanden, um nützlich zu sein.
Heute ändert sich das dank der Arbeit von Karl Moritz Hermann bei Google DeepMind in London und ein paar Kumpels. Diese Leute sagen, die spezielle Art und Weise, wie die Daily Mail und CNN Online-Nachrichtenartikel schreiben, erlaube es, sie auf diese Weise zu verwenden. Und die schiere Menge an online verfügbaren Artikeln schafft zum ersten Mal eine Datenbank, die Computer verwenden können, um zu lernen und dann darauf zu antworten. Mit anderen Worten, DeepMind verwendet Daily Mail- und CNN-Artikel, um Computern das Lesen beizubringen.
Die Deep-Learning-Revolution ist hauptsächlich auf zwei Durchbrüche zurückzuführen. Die erste bezieht sich auf neuronale Netze, bei denen Informatiker neue Techniken entwickelt haben, um Netze mit vielen Schichten zu trainieren, eine Aufgabe, die aufgrund der Anzahl von Parametern, die fein abgestimmt werden müssen, schwierig war. Die neuen Techniken produzieren im Wesentlichen fertige Netze, die bereit sind zu lernen.
Aber ohne eine Datenbank, aus der man lernen kann, ist ein neuronales Netz wenig hilfreich. Eine solche Datenbank muss sorgfältig kommentiert werden, damit die Maschine einen Goldstandard hat, von dem sie lernen kann. Beispielsweise muss die Trainingsdatenbank für die Gesichtserkennung Bilder enthalten, auf denen Gesichter und ihre Position im Rahmen eindeutig identifiziert werden können. Und damit die Bilder möglichst viele Gesichtsarrangements abdecken, müssen die Datenbanken riesig sein.
Das ist seit kurzem dank Crowdsourcing-Diensten wie Amazons Mechanical Turk möglich. Verschiedene Teams haben diese Art von Goldstandard-Datenbank erstellt, indem sie Menschen Bilder gezeigt und sie gebeten haben, Begrenzungsrahmen um die Gesichter zu ziehen, die sie enthalten.
Aber das Erstellen einer ähnlich annotierten Datenbank für das geschriebene Wort ist viel schwieriger. Sicher, es ist möglich, Sätze zu extrahieren, die wichtige Punkte enthalten. Aber diese sind keine große Hilfe, weil jeder Maschinenalgorithmus schnell lernt, den Text nach der gleichen Phrase zu durchsuchen, eine triviale Aufgabe für einen Computer.
Stattdessen muss die Anmerkung den Inhalt des Textes beschreiben, ohne darin zu erscheinen. Um die Verknüpfung zu verstehen, muss ein Lernalgorithmus dann über das bloße Vorkommen von Wörtern und Phrasen hinaus auch auf deren grammatikalische Verknüpfungen und kausale Zusammenhänge schauen.
Das Erstellen einer solchen Datenbank ist leichter gesagt als getan. Informatiker haben kleine Versionen von Hand erzeugt, aber diese sind zu klein, um für ein neuronales Netzwerk von großem Nutzen zu sein. Und es scheint wenig Möglichkeiten zu geben, größere von Hand zu erstellen, da Menschen im Allgemeinen schlecht darin sind, Texte genau zu kommentieren, es sei denn, sie sind spezialisierte Redakteure.
Rufen Sie die Daily Mail-Website, MailOnline und CNN online auf. Diese Sites zeigen Nachrichtenartikel an, wobei die Hauptpunkte der Geschichte als Stichpunkte angezeigt werden, die unabhängig vom Text geschrieben werden. Entscheidend ist, dass diese Zusammenfassungen abstrakt sind und nicht einfach Sätze aus den Dokumenten kopieren, sagen Hermann und Co.
Das legt sofort einen Weg nahe, eine annotierte Datenbank zu erstellen: Nehmen Sie die Nachrichtenartikel als Texte und die Zusammenfassungen der Stichpunkte als Annotation.
Das DeepMind-Team geht jedoch noch weiter. Sie weisen darauf hin, dass es immer noch möglich ist, die Antwort auf viele Fragen mit einfachen Wortsuchansätzen zu erarbeiten.
Sie geben das folgende Beispiel für ein Problem, das als Cloze-Abfrage bekannt ist und für dessen Lösung häufig maschinelle Lernalgorithmen verwendet werden. Hier ist das Ziel, X in diesen modifizierten Schlagzeilen der Daily Mail zu identifizieren: a) Der Hi-Tech-BH, der Ihnen hilft, Brust X zu schlagen; b) Könnte Saccharin helfen, X zu schlagen?; c) Können Fischöle helfen, Prostata X zu bekämpfen?
Hermann und Co weisen darauf hin, dass eine einfache Art von Data-Mining-Algorithmus namens Ngram-Suche die Antwort leicht finden könnte, indem nach Wörtern gesucht wird, die neben all diesen Sätzen am häufigsten vorkommen. Die Antwort ist natürlich das Wort Krebs.
Um diese Art von Lösung zu vereiteln, anonymisieren Hermann und Co. den Datensatz, indem sie die Akteure in Sätzen durch eine generische Beschreibung ersetzen. Ein Beispiel für einen Originaltext aus der Daily Mail ist dieser: Der BBC-Produzent, der angeblich von Jeremy Clarkson geschlagen wurde, wird keine Anklage gegen den Top Gear-Moderator erheben, sagte sein Anwalt am Freitag. Clarkson, der eine der meistgesehenen Fernsehsendungen der Welt moderierte, wurde am Mittwoch von der BBC fallen gelassen, nachdem eine interne Untersuchung des britischen Senders ergab, dass er Produzent Oisin Tymon einem unprovozierten körperlichen und verbalen Angriff ausgesetzt hatte.
Eine anonymisierte Version dieses Textes wäre die folgende:
Der ent381 Produzent angeblich von getroffen ent212 wird keine Anklage gegen die erheben ent153 Gastgeber, sagte sein Anwalt am Freitag. ent212 , der eine der meistgesehenen Fernsehsendungen der Welt moderierte, wurde von der fallen gelassen ent381 Mittwoch nach einer internen Untersuchung durch die ent180 Sender stellte fest, dass er Produzent unterworfen hatte ent193 zu einem unprovozierten körperlichen und verbalen Angriff.
Auf diese Weise ist es möglich, die folgende Lückentext-Abfrage zu konvertieren, um X zu identifizieren Produzent X wird keine Anklage gegen Jeremy Clarkson erheben, sagt sein Anwalt zu Produzent X wird keine Anklage erheben ent212 , sagt sein Anwalt .
Und die erforderliche Antwort ändert sich von Oisin Tymon zu ent212 .
Auf diese Weise ist es dem anonymisierten Akteur nur möglich, sich mit einem gewissen Verständnis der grammatikalischen Verbindungen und kausalen Beziehungen zwischen den Entitäten in der Geschichte zu identifizieren.
Die resultierende Datenbank ist riesig und besteht aus 110.000 Artikeln von CNN und 218.000 Artikeln von der Daily Mail-Website.
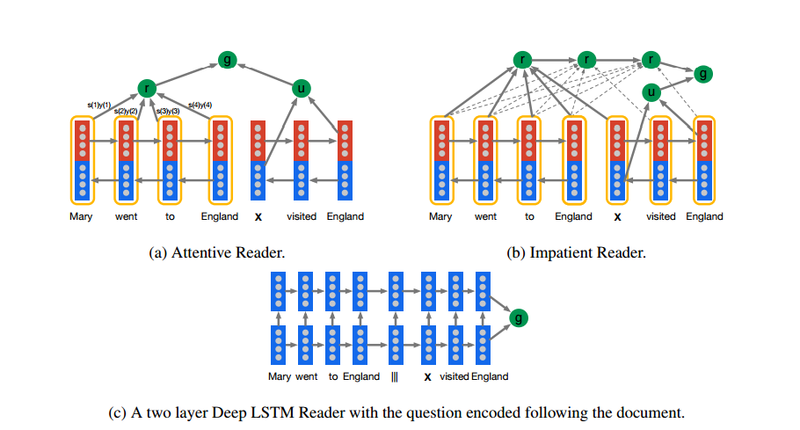
Nachdem sie zum ersten Mal eine solche Datenbank erstellt haben, können Hermann und Co nicht widerstehen, sie zu verwenden, um verschiedene maschinelle Lerntechniken auf Herz und Nieren zu prüfen. Sie vergleichen herkömmliche Techniken zur Verarbeitung natürlicher Sprache, wie etwa das Messen des Abstands zwischen Wortkombinationen, und modernere neuronale Netzwerkansätze.
Die Ergebnisse zeigen deutlich, wie leistungsfähig neuronale Netze geworden sind. Hermann und Co sagen, dass die besten neuronalen Netze 60 Prozent der an sie gerichteten Anfragen beantworten können. Sie schlagen vor, dass diese Maschinen alle Anfragen beantworten können, die auf einfache Weise strukturiert sind, und nur mit Anfragen zu kämpfen haben, die komplexere grammatikalische Strukturen haben.
Es gibt natürlich einige Vorbehalte. Am offensichtlichsten ist, dass Artikel aus der Daily Mail und CNN eine sehr spezifische Grundstruktur haben, die sich von anderen nicht-journalistischen Formen des Schreibens unterscheidet. Wie diese zugrunde liegende Struktur die Ergebnisse beeinflusst, ist nicht klar.
Es ist auch nicht klar, wie diese Maschinen im Vergleich zu menschlichen Fähigkeiten abschneiden, was mit Diensten wie Mechanical Turk leicht herauszufinden wäre. Das würde die Behauptung von DeepMind in Zusammenhang bringen, die im Titel seines Papiers impliziert ist, dass diese Maschinen lernen, das zu verstehen, was sie lesen.
Nichtsdestotrotz ist dies eine interessante Arbeit, die den Rahmen für einige faszinierende Entwicklungen in der nahen Zukunft bereitet. Maschinenlesung kommt; die frage ist nur wie schnell.
Ref: arxiv.org/abs/1506.03340 : Maschinen das Lesen und Verstehen beibringen