211service.com
KI-Maschine versucht, Comics zu verstehen … und scheitert
Die Liste der Aktivitäten, bei denen Maschinen mit künstlicher Intelligenz Menschen besiegt haben, wächst mit alarmierender Geschwindigkeit. Gesichtserkennung, Objekterkennung, Schach, Go, verschiedene Videospiele und zahlreiche andere Aufgaben sind alle in diesem Kampf gefallen.
Da liegt es nahe, nach den Arten von Aufgaben zu fragen, mit denen Maschinen noch Schwierigkeiten haben. Wo herrscht noch der Mensch?
Heute bekommen wir dank der Arbeit von Mohit Iyyer von der University of Maryland in College Park und einigen Freunden eine Art Antwort. Diese Leute fragen, wie gut künstliche Intelligenz Comics verstehen kann, und können kaum widerstehen, in die Luft zu schlagen, um zu enthüllen, dass die Maschinen im Vergleich zu Menschen einen traurigen zweiten Platz einnehmen.
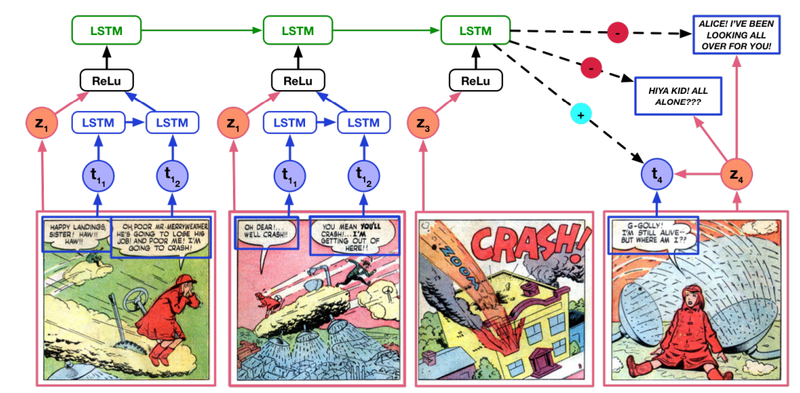
Comics erzählen Geschichten mit einer Abfolge von Panels, die aus handgezeichneten und oft stark stilisierten Bildern bestehen, die sich in ihrem Charakter stark von Fotografien unterscheiden. Diese Tafeln sind auch mit Text in Form von Gedankenblasen, Sprechblasen und Erzählkästchen kommentiert.
Text und Bild arbeiten eng zusammen; oft so nah, dass man der Geschichte allein anhand der Bilder oder des Textes nicht folgen kann. Selbst dann muss der Leser erhebliche Rückschlüsse und Extrapolationen ziehen, wenn er von Panel zu Panel springt. Viele Details müssen vom Leser ausgefüllt werden.
Es ist das, was der Schöpfer vor seinen Seiten verbirgt, was Comics wirklich interessant macht, die unausgesprochenen Gespräche und unsichtbaren Aktionen, die in den Räumen (oder Rinnen) zwischen benachbarten Panels lauern, sagen Iyyer und Co. Beim Entschlüsseln dieser Details entsteht die Geschichte in der Vorstellungskraft der Leser.
Dieser komplexe Prozess, bei dem ein einzelnes Panel angezeigt und verstanden wird, wie es mit vorherigen verbunden ist, wird als Abschluss bezeichnet. Und im Moment ist es eine einzigartige menschliche Fähigkeit.
Aus diesem Grund haben Iyyer und Co. ein Experiment entwickelt, um zu testen, wie gut Maschinen es auch ausführen können.
Diese Jungs erstellen zunächst eine große Datenbank mit Comic-Geschichten, mit denen sie Deep-Learning-Maschinen trainieren können. Sie erstellen dies anhand von Comics, die zwischen den 1930er und 1950er Jahren veröffentlicht wurden. Dies war das sogenannte goldene Zeitalter der Comics, das Ende der 1950er Jahre endete, als in den USA strenge Zensurvorschriften eingeführt wurden. Das Urheberrecht an diesen Veröffentlichungen ist inzwischen abgelaufen und sie sind auf einer Website namens Digital Comics Museum in öffentlich zugänglich in Form von vom Benutzer hochgeladenen JPEGs.
Iyyer und Co. verwendeten 4.000 der bestbewerteten Comics auf der Website und erstellten eine Datenbank mit über 1,2 Millionen Panels. Sie verwenden optische Zeichenerkennung, um den Text auf jedem Panel zu digitalisieren.
Um den Abschluss zu testen, entwickeln Iyyer und Co eine Reihe von Experimenten, bei denen einer Maschine eine Reihe von Panels gezeigt wird und sie dann aus einer Reihe möglicher Antworten vorhersagen muss, was als nächstes kommt. Die Aufgabe kann darin bestehen, das nächste Bild oder den nächsten Text vorherzusagen oder den Text einem bestimmten Zeichen zuzuordnen.
Zuerst muss die Maschine lernen, wie Comics funktionieren. Also fütterte das Team einen Teil der Panels und Texte mit verschiedenen maschinellen Lernalgorithmen, damit sie lernen konnten, wie Panels aufeinander folgen. Diese Maschinen sind vortrainiert, um Objekte zu erkennen, jedoch in natürlichen Bildern und nicht in Cartoons.
Nachdem die Maschinen trainiert wurden, testet das Team sie dann auf einer Reihe von Panels, die sie noch nicht gesehen haben, und bittet sie, das nächste Bild oder den nächsten Text in der Serie vorherzusagen.
Die Ergebnisse sind zum Anheben der Augenbrauen. Während Menschen den nächsten Text oder das nächste Bild in mehr als 80 Prozent der Fälle richtig vorhersagen können, kommen die Maschinen nie an diese Genauigkeit heran. Keine der Architekturen übertrifft menschliche Grundlinien, was für die Schwierigkeit spricht, Comics zu verstehen, sagen Iyyer und Co. Bildmerkmale, die von Modellen gewonnen wurden, die auf natürlichen Bildern trainiert wurden, können die große Vielfalt künstlerischer Stile nicht erfassen, und Textmodelle kämpfen mit dem Reichtum und der Mehrdeutigkeit umgangssprachlicher Dialoge, die stark von visuellen Kontexten abhängig sind.
Das ist nicht überraschend angesichts des gesunden Menschenverstandes, der erforderlich ist, um diesen Geschichten zu folgen, und des kulturellen Wissens, das erforderlich ist, um die Logik des Geschichtenerzählens in Comics zu verstehen.
Der Mensch ist also zumindest im Moment noch Meister dieser Aufgabe.
Aber die Maschinen werden sicherlich besser werden, wenn sie die sozialen und Schlussfolgerungsfähigkeiten erlernen, von denen wir glauben, dass sie uns menschlich machen.
Und das wirft eine interessante Möglichkeit auf. KI-Maschinen haben Menschen beim Schach geschlagen, Gefahr! , Go und viele andere Aufgaben. Vielleicht sollte ihre nächste Herausforderung darin bestehen, Comics besser zu verstehen als Menschen und vielleicht sogar Erzählungen auf diese Weise zu erstellen. Das würde Google DeepMind oder einen seiner Konkurrenten gegen die Charaktere in Marvel oder DC Comics stellen. Der perfekte Kampf und sicherlich einer, der Spaß machen würde.
Ref: arxiv.org/abs/1611.05118 : Die erstaunlichen Geheimnisse der Gosse: Schlussfolgerungen zwischen Panels in Comic-Erzählungen ziehen